Apache Beam Model の概要を学ぶ
目次
Apache Beam モデルとは?
概要
公式に出てくるのは以下のような文言だ。
- 統一されたApache Beam モデル
- バッチおよびストリーミング データ処理を行う最も簡単な方法。
- 一度書けばどこでも実行できる、ミッションクリティカルな実稼働ワークロード向けのデータ処理。
なにやら凄そうな雰囲気が漂ってくる。
仕組み
その仕組みは、以下の3つのステップで成り立つとのこと。
データソーシング
- Beam は、オンプレミスかクラウドかに関係なく、サポートされているさまざまなソースからデータを読み取ります。
情報処理
- Beam は、バッチとストリーミングの両方のユースケースでビジネス ロジックを実行します。
データ書き込み
- Beam は、データ処理ロジックの結果を業界で最も一般的なデータ シンクに書き込みます。
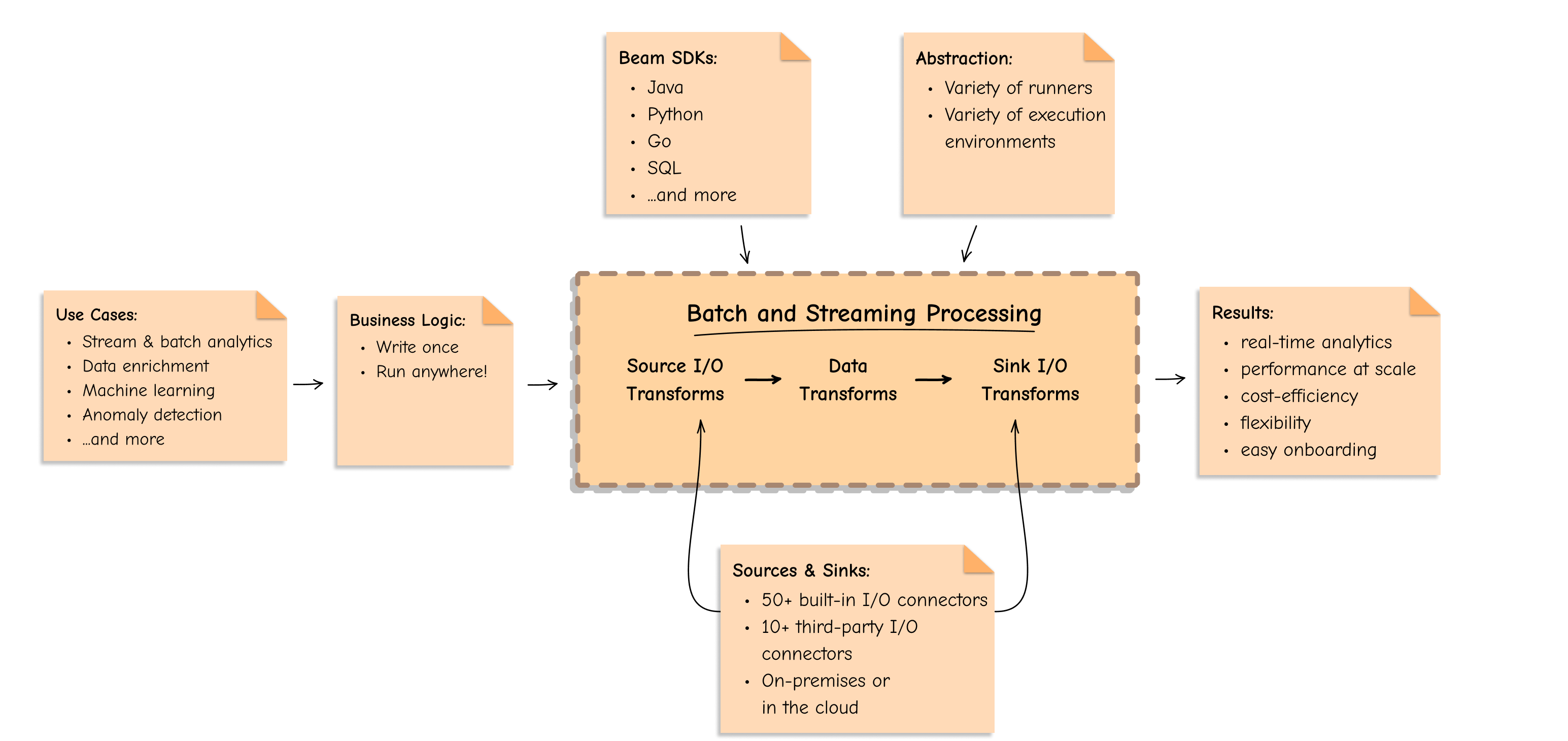
- ストリーミングやバッチ処理等のユースケースを
Source -> Data Transforms -> Sinkで吸収することができる。 - 言語はJava, Python, Go, SQLなどで記述でき、I/Oライブラリは充実しており、ロジックは一度書くだけで様々な環境で動かすことができるとのこと。
Scalaの Akka Streams にも似たような概念があったな感じた。あちらはスレッドを管理するので複雑だが。 むしろ、そういったストリーミングなユースケースを抽象化して扱いやすくしましょうというのがBeamのモチベーションなのかもしれない。
機能
強力な抽象化
- Apache Beam モデルは、個々のワーカーの調整、ソース読み込みやシンク書き込みなどの、分散データ処理について回る低レベルな詳細からあなたを高度な抽象化で守ります。
- パイプライン抽象化は、データの処理タスクの全データ・ステップをカプセル化し、これら抽象化されたものを考えるだけで済みます。
- 高度な抽象化によって、データと実行時特性が分離され、大規模な分散データ処理の仕組みが単純化される。
統一プログラミングモデル
- Apache Beam はビジネスロジックを一度書けば良いものにし、バッチ・ストリーミングのデータパイプラインを、OSSランナー経由のオンプレミスからGoogle Cloud Dataflowのようなマネージドサービスで実行する柔軟性を提供します。
- Beamモデルを中心に、複数のデータ処理エンジンとSDKを統合しているため、大規模な共通のデータインフラを簡単に作成する方法が提供されている。
クロスランゲージ
- 様々な言語が選択できる。また、言語変換機能を用いて全てのメンバーが好きなプログラミング言語で記述することができます。
- Apache Beam は、特定の言語・技術スタックに縛られることを防ぎます。
移植性
- 様々な実行エンジン・ランナーを自由に選択でき、ベンダーに依存しません。
- オープンソース(Apache Flink や Spark等)やプロプライエタリ(Google Cloud DataflowやAWS KDA等)の言語や実行環境間でポータブルなデータパイプラインを書くことができます。
拡張性
- Apache Beam はオープンソースであり、拡張可能です。TensorFlow Extended や Apache Hop のようなプロジェクトがApache Beam 上に構築されており、“一度書けばどこでも実行できる “能力を活用している。
導入の容易さ
-
Apache Beam は、低レベルの詳細を抽象化し、プログラミング言語を自由に選択できるため、導入や実装が容易です。
-
Apache Beam のデータパイプラインはジェネリックトランスフォームで表現されるため、理解しやすく保守しやすい。
-
Apache Beam のユーザは、価値達成までの時間が大幅に短縮されたと報告しています。最も顕著なのは、パイプラインの開発と導入に必要な時間が短縮され、数日から数時間に短縮されたことです。
-
Apache Beam の実行環境が気になって実行環境表をみてみると結構ある。
ロードマップ
-
特定の営利団体ではなく、プロジェクト管理委員会(PMC)によって管理、運営されているとのこと。
-
Beam はPMCがユーザーの利益となるようなビジョンを掲げ、主要コンポーネントにはそれぞれロードマップが設定されている。
-
以下に全体のロードマップをざっくり紹介する。
ポータビリティフレームワーク
- 移植性は、任意の SDK で作成されたパイプラインを任意のランナー上で実行するという、Beam の主要なビジョンです。
- これは、Java、Python、Go、およびすべての Beam ランナーにわたる横断的な取り組みです。
- 移植性は現在、Flink ランナーと Spark ランナーでサポートされています。
Go SDK
- Go SDKは最新のSDKであり、完全にポータビリティ・フレームワークで構築された最初のSDKです。
Python 3 サポート
- Apache Beam 2.14.0以降はPython 3.5、3.6、3.7をサポートしています。
- Python 3ユーザのエクスペリエンスを改善し続け、Python 2のサポートを段階的に終了する予定です。
Java 17 サポート
- Java SDKは、Javaの次期LTS(Long Term Support)バージョンのサポートを追加することを熱望している。
SQL
- BeamのSQLモジュールは、SQLだけでバッチやストリーミングパイプラインを作成できるように急速に成熟しつつあります。
移植可能なスキーマ
- スキーマはSDKやランナーがユーザーデータの構造を理解し、リレーショナル最適化の可能性を解き放つことを可能にする。
- ポータブルなスキーマはPythonとJavaの行間の互換性を可能にします。特に興味深いユースケースは、Beamのクロスランゲージ・サポートによるSQL(Javaで実装)とPython SDKの組み合わせです。
今後の方向性
- 全体を眺めた所感は、Go言語をはじめとしてユニバーサルな言語での開発を目指しているモチベーションが高いというところでしょうか。
- しかしながらApache Beamを必要とするユースケースが限定的であるところを踏まえると、Go言語 + 1,2言語あたりで緩やかに収束しそうな気もします。
- Go言語をメインに扱うプロダクトは多いので、まずそこのI/Oサポートが行われると心強いところです。(貢献しろ)